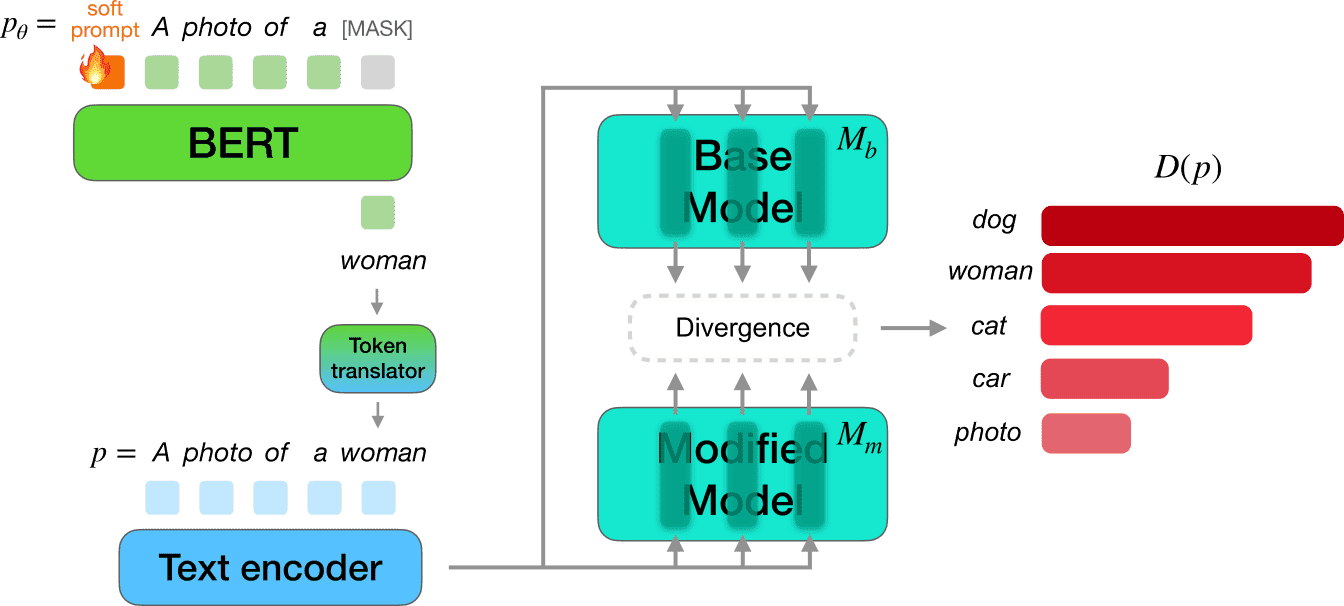
DriftScope optimizes a soft prompt to find the tokens whose visual concepts diverge most between a base model Mb and its adapted counterpart Mm, producing a ranked drift report for pre-deployment auditing.
Adapting pre-trained text-to-image diffusion models, whether to learn new visual concepts or erase unwanted ones, is routinely evaluated on its intended effects alone. We argue this framing is incomplete. Through sparse autoencoder analysis and zero-shot classification, we demonstrate that adaptation systematically damages semantically unrelated concepts in ways that aggregate metrics structurally cannot surface: when damage is severe enough for FID and KID to respond, the model is already nearly unusable; when the model remains functional, FID and KID stay flat while specific classes silently suffer worst-case zero-shot accuracy drops of up to 18.9 points and concept-level distributions shift dramatically. This pattern appears at both ends of the adaptation spectrum (concept customization and concept unlearning), suggesting it is a systematic consequence of weight-level modification rather than an artifact of any particular method. To surface this hidden drift before deployment, we introduce DriftScope, a prompt-level diagnostic tool that takes any two model checkpoints and returns a ranked list of tokens whose visual concepts have shifted most between them. DriftScope optimizes a soft prompt to attribute drift at the token level without requiring access to real data or model internals. The result is an interpretable, concept-level audit that aggregate evaluation cannot provide.
EraseDiff: FID and KID spike, zero-shot collapses. Metrics catch it — but the model is already destroyed.
SPM: FID stays at 3.6, KID at 0.00002 — yet specific concepts are quietly eroded. Aggregate metrics see nothing.
DreamBooth: mean accuracy is fine, but the standard deviation reveals some classes are severely damaged while others are untouched.
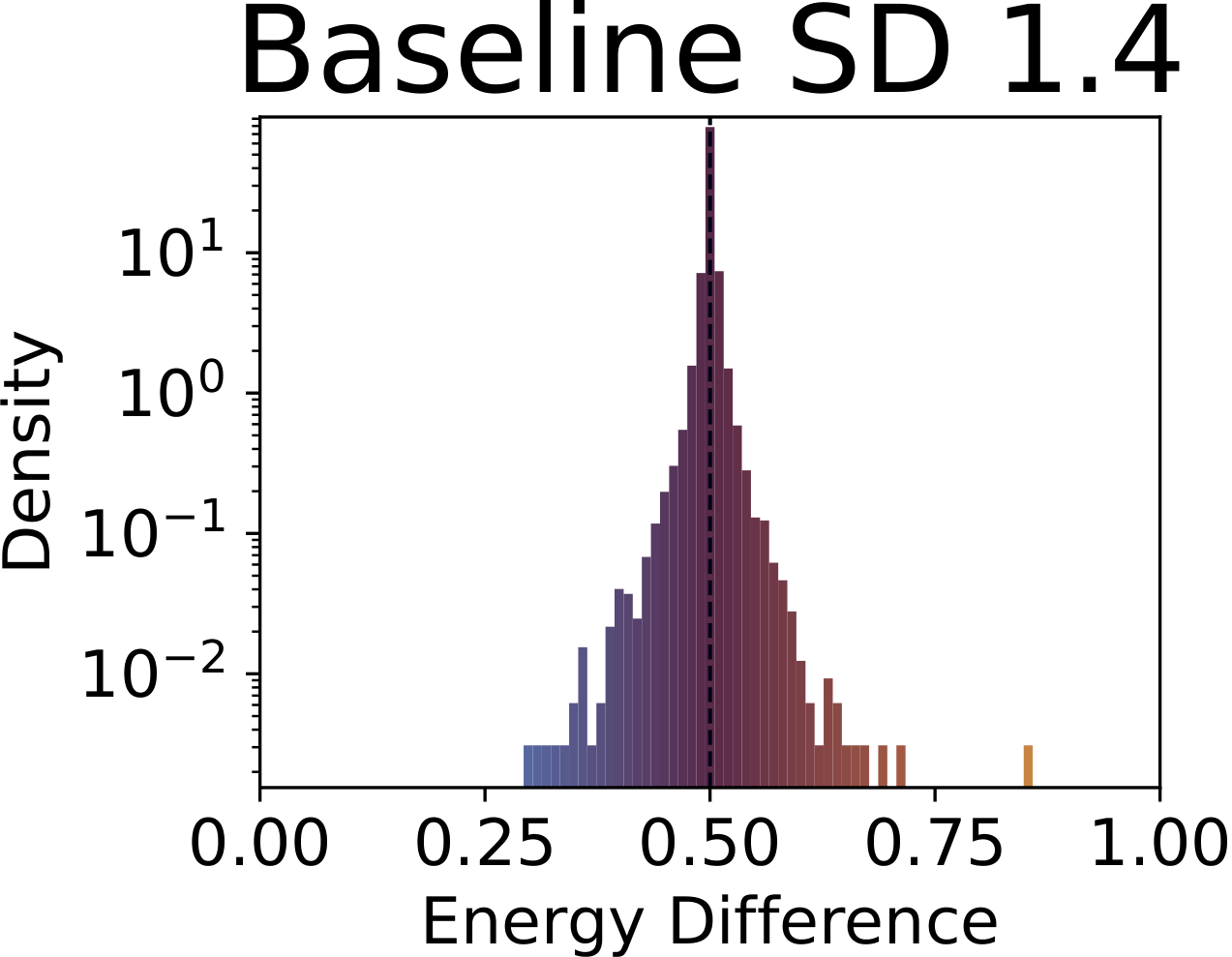
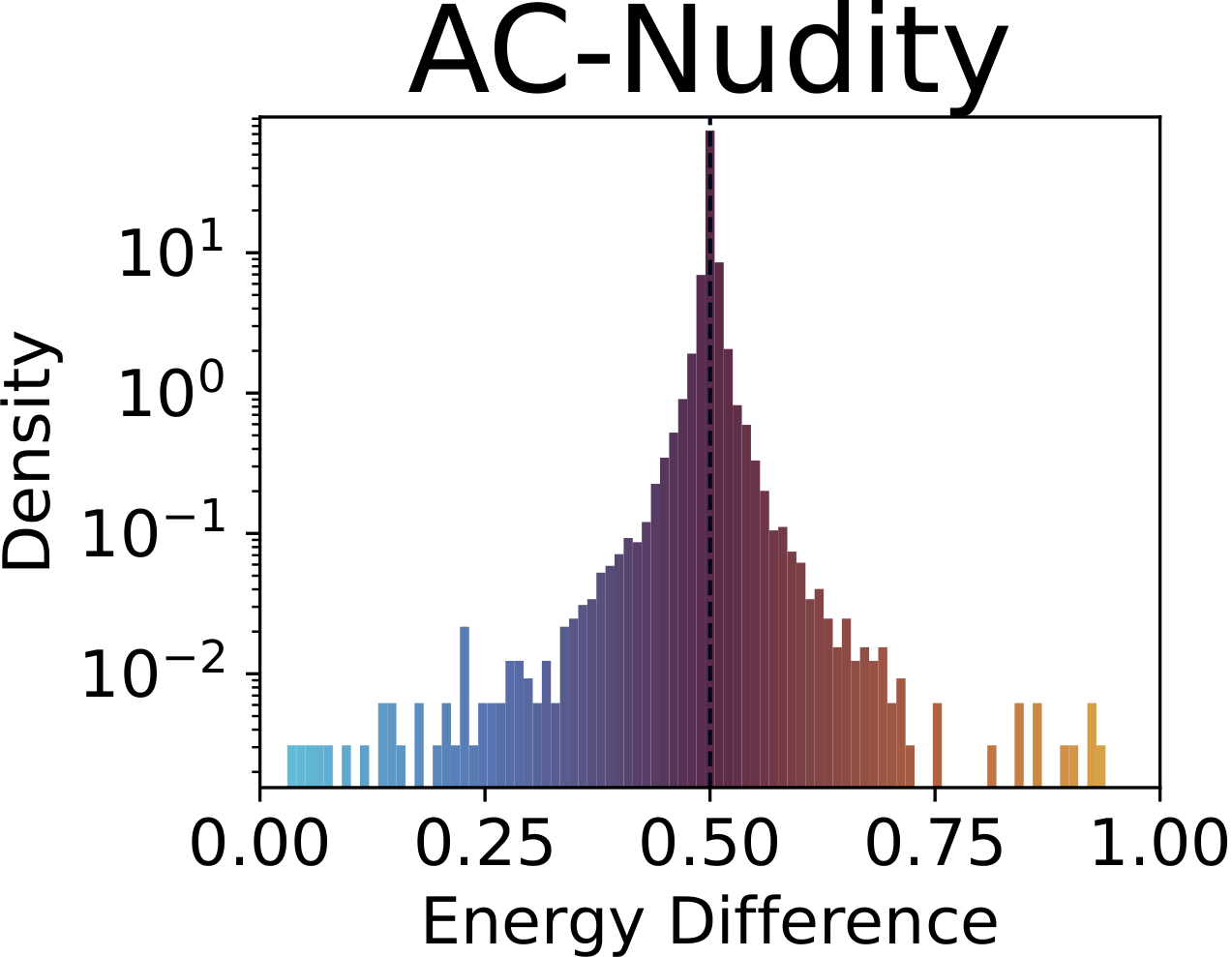
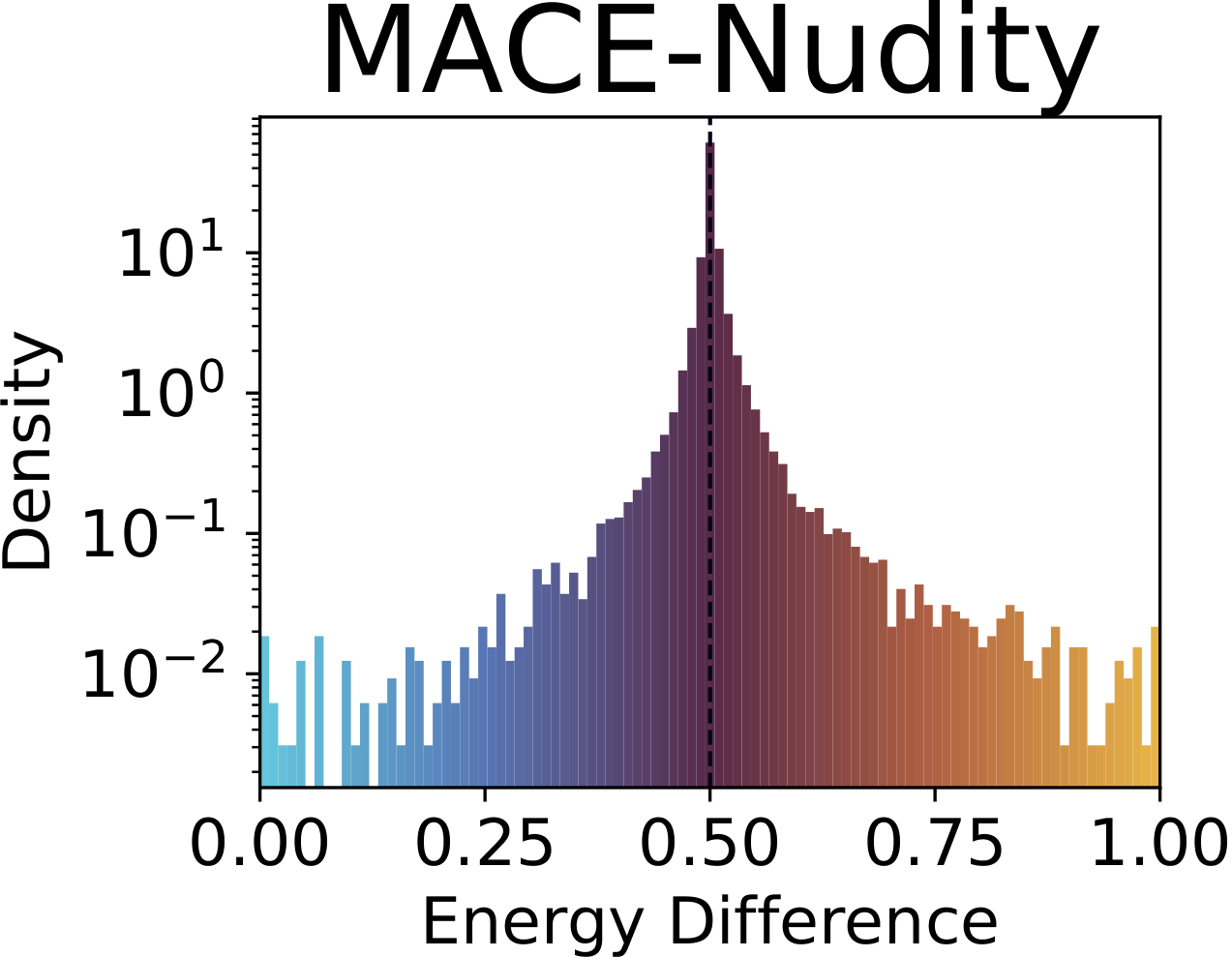
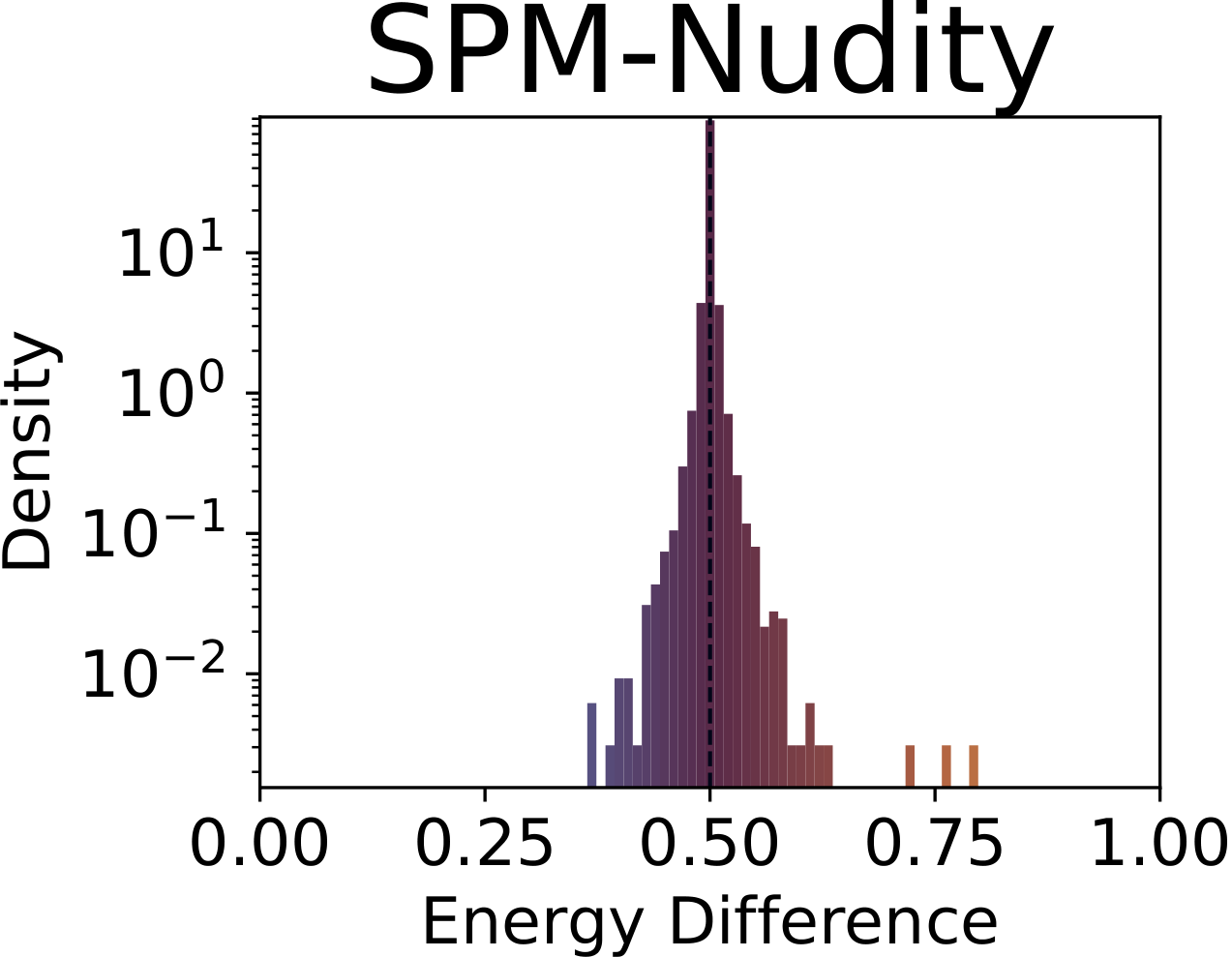
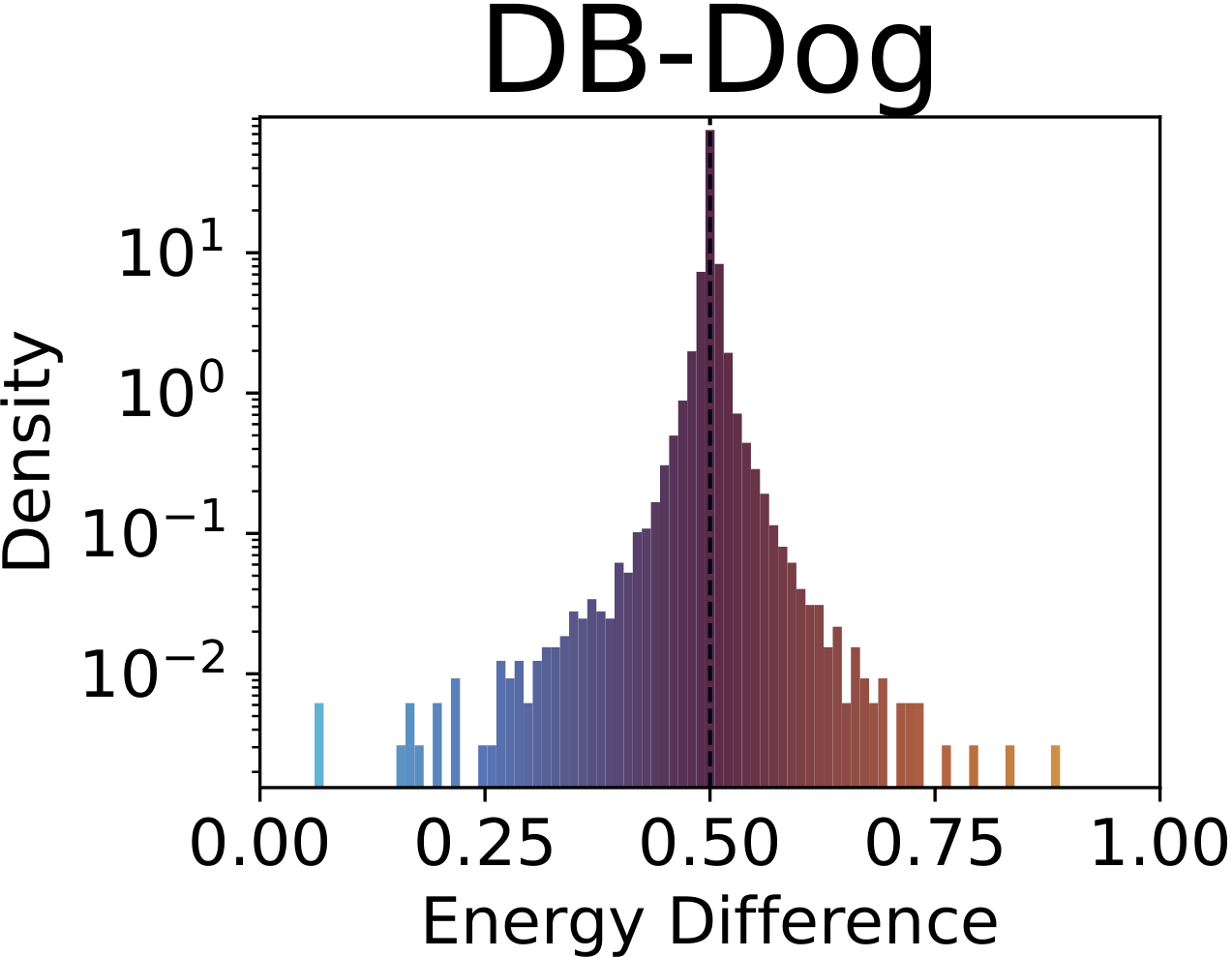
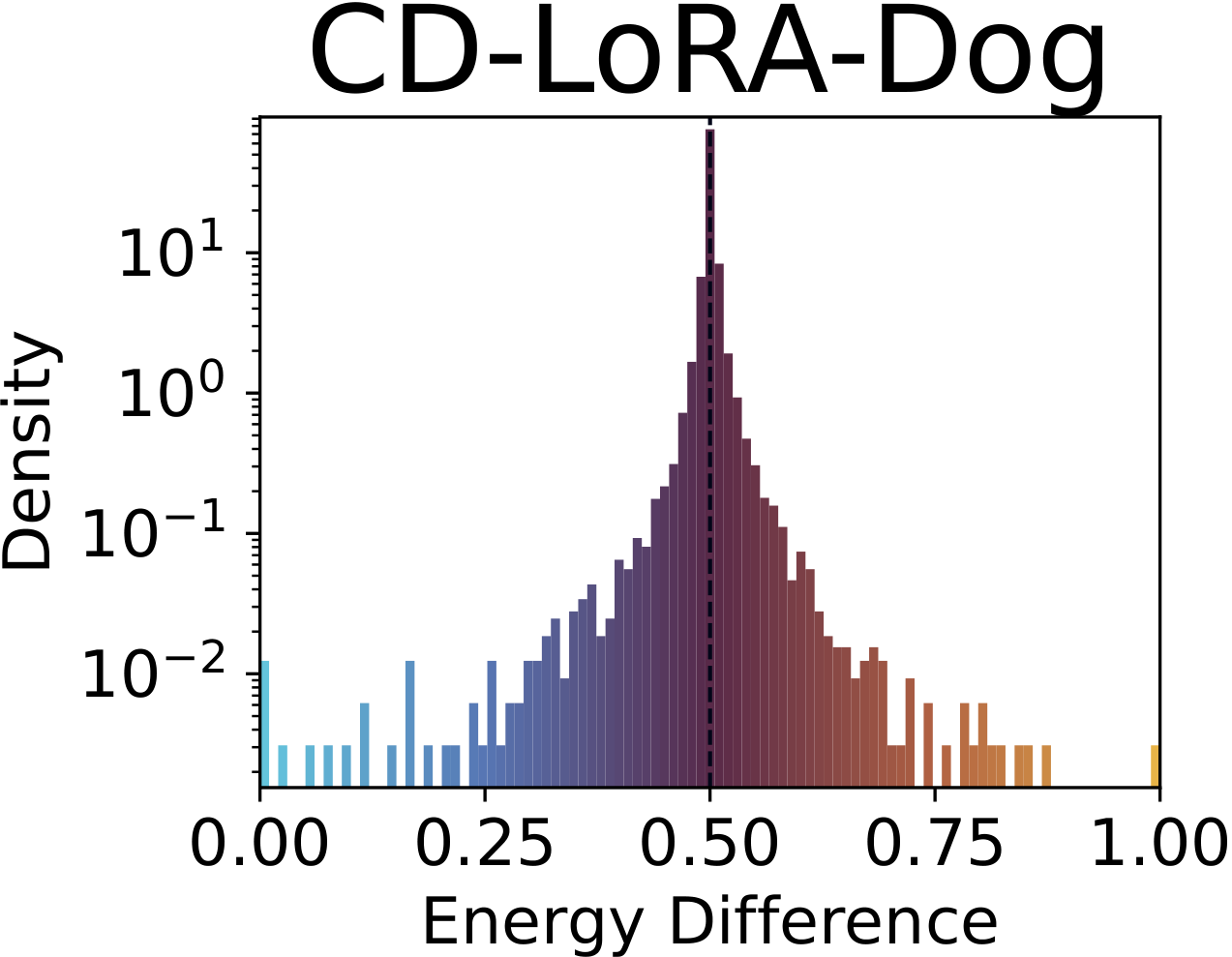
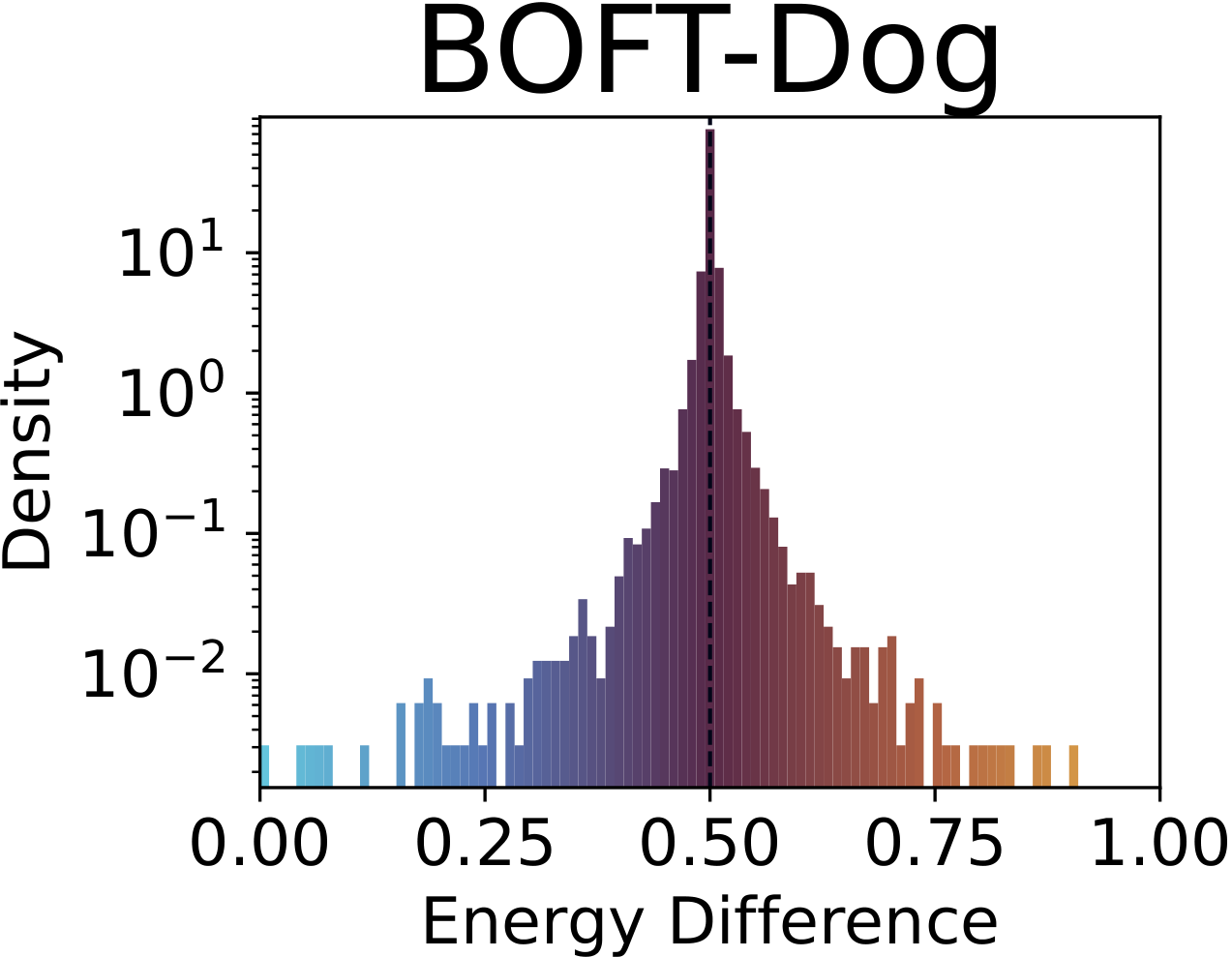
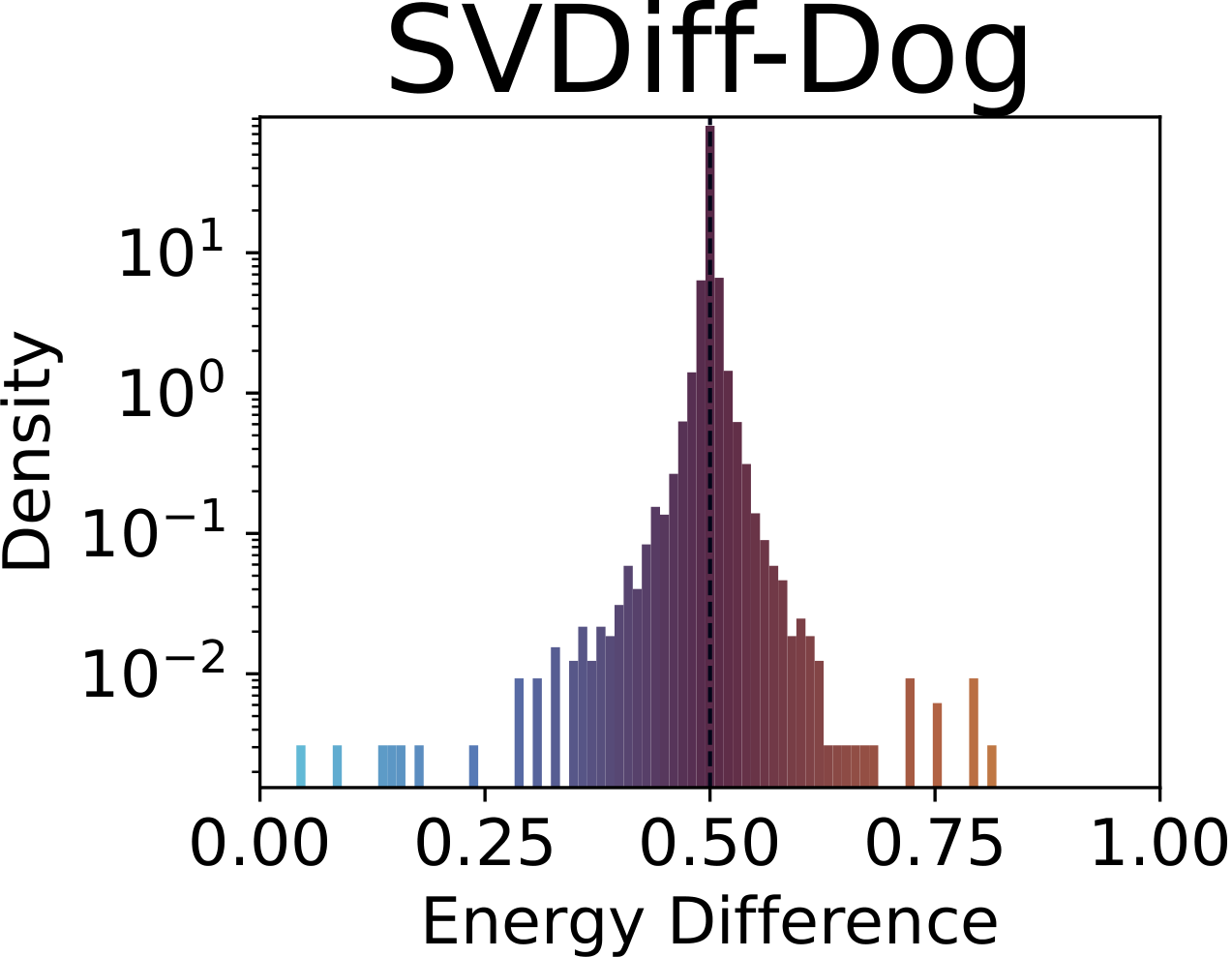
Fig. 1. Distribution of SAE drift scores across concepts. The baseline (top-left) concentrates sharply around 0.5; adapted models show heavy-tailed distributions indicating systematic concept-level drift beyond the intended target. Top row: concept unlearning (nudity). Bottom row: concept customization (dog).
Two case studies from the paper. Select an adaptation to see the tokens DriftScope ranked as most affected — often collateral damage no practitioner would anticipate.

(a) Maximized drift.

(b) Minimized drift.
Fig. 3. Prompts found by DriftScope that (a) maximize and (b) minimize cross-attention drift between model checkpoints. Results for unlearning methods (ESD, SPM, Scissorhands) and DreamBooth LoRA customization (dog concept) across Stable Diffusion 1.5, 2.1, and 3.5-Medium.
DriftScope is not limited to short, single-concept prompts. Collateral damage surfaces equally in longer, naturalistic inputs: in the DreamBooth dog fine-tune, Facebook emerges as a high-drift token despite having no relation to the adapted concept, and color-bearing prompts show stylistic drift propagating to modifiers the practitioner would never expect to be affected.

Fig. 4. High-drift image pairs from SD 2.1 under long, naturalistic inputs sourced from PromptHero, for a DreamBooth model fine-tuned on a dog concept. Each pair shows the base model generation (left) alongside the adapted model generation (right).